Research Summary
I like to focus on problems which closely impact our community and my work till now has been focused on understanding the nature of these problems. I am interested in solutions which build on machine learning, statistics, applied probability, optimization, and simulation.
In addition to always looking to learn and solve problems, I like photography and working for the community. During my undergraduate years at BITS Pilani I founded Bumbling.Tumbling.Clicking. through which we worked towards promoting volunteering spirit and active citizenship among the youth.
Interests: Optimization, Reinforcement Learning, Machine Learning Theory, and Large Language Models.
Publications
-
Abstract: Post-training of LLMs with RLHF, and subsequently preference optimization algorithms such as DPO, IPO, etc., made a big difference in improving human alignment. However, all such techniques can only work with a single (human) objective. In practice, human users have multiple objectives, such as helpfulness and harmlessness, and there is no natural way to aggregate them into a single objective. In this paper, we address the multi-objective preference-alignment problem, where a policy must optimize several, potentially conflicting, objectives. We introduce the Multi-Objective Preference Optimization (MOPO) algorithm, which frames alignment as a constrained KL-regularized optimization: the primary objective is maximized while secondary objectives are lower-bounded by tunable safety thresholds. Unlike prior work, MOPO operates directly on pairwise preference data, requires no point-wise reward assumption, and avoids heuristic prompt-context engineering. The method recovers policies on the Pareto front whenever the front is attainable; practically, it reduces to simple closed-form iterative updates suitable for large-scale training. On synthetic benchmarks with diverse canonical preference structures, we show that MOPO approximates the Pareto front. When fine-tuning a 1.3B-parameter language model on real-world human-preference datasets, MOPO attains higher rewards and yields policies that Pareto-dominate baselines; ablation studies confirm optimization stability and robustness to hyperparameters.
-
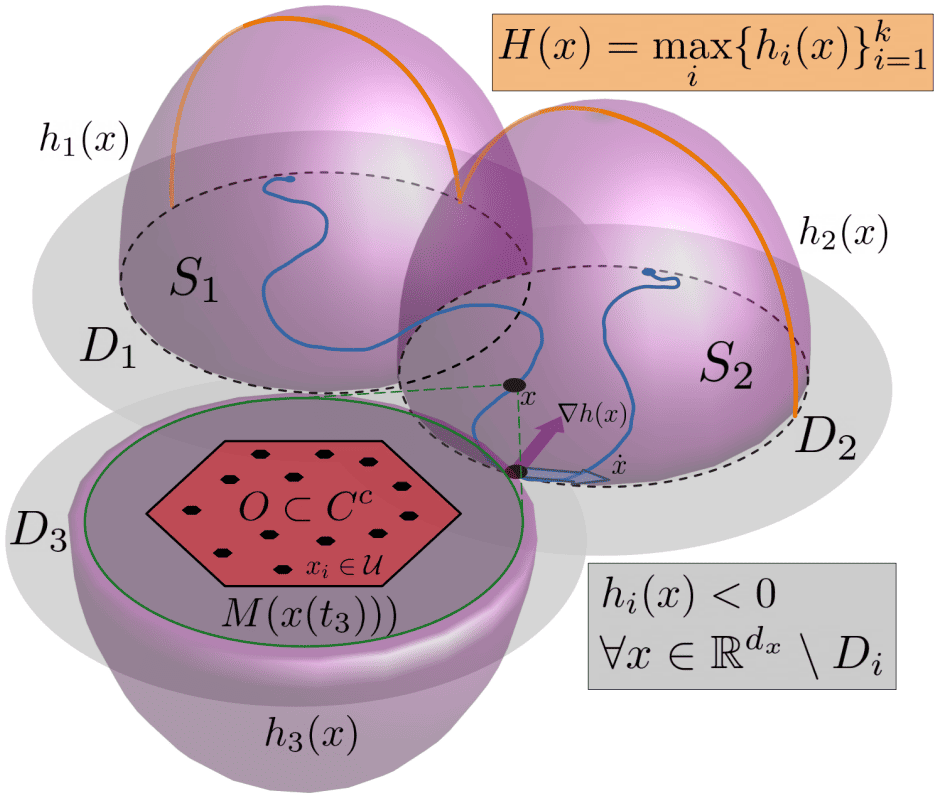
Abstract: We address the problem of best policy identification in preference-based reinforcement learning (PbRL), where learning occurs from noisy binary preferences over trajectory pairs rather than explicit numerical rewards. This approach is useful for post-training optimization of generative AI models during multi-turn user interactions, where preference feedback is more robust than handcrafted reward models. In this setting, learning is d riven by both an offline preference dataset -- collected from a rater of unknown 'competence' -- and online data collected with pure exploration. Since offline datasets may exhibit out-of-distribution (OOD) biases, principled online data collection is necessary. To address this, we propose Posterior Sampling for Preference Learning (PSPL), a novel algorithm inspired by Top-Two Thompson Sampling, that maintains independent posteriors over the true reward model and transition dynamics. We provide the first theoretical guarantees for PbRL in this setting, establishing an upper bound on the simple Bayesian regret of PSPL. Since the exact algorithm can be computationally impractical, we also provide an approximate version that outperforms existing baselines.
-
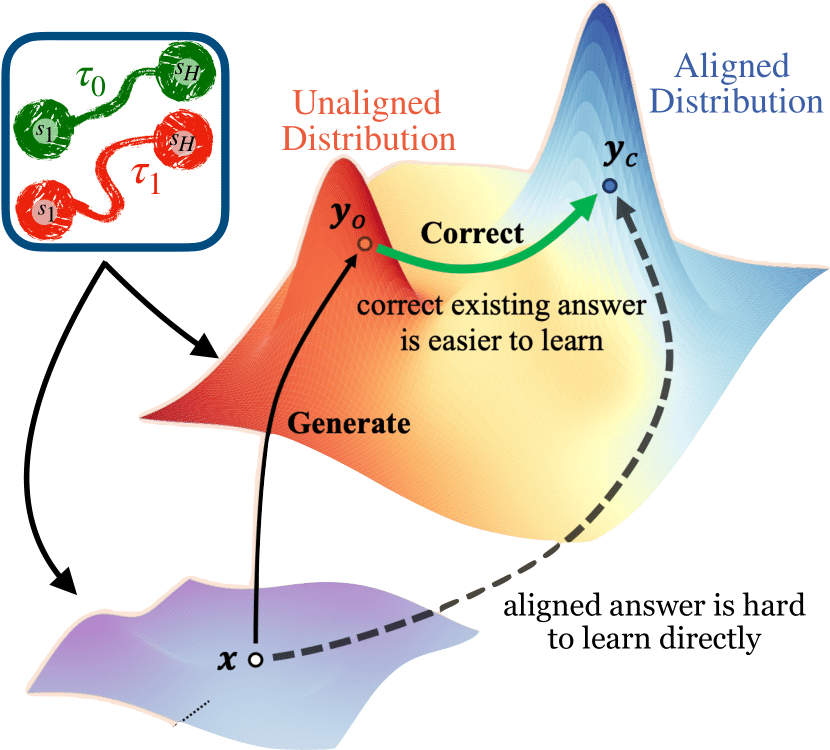
Abstract: Reinforcement Learning with Human Feedback (RLHF) is at the core of fine-tuning methods for generative AI models for language and images. Such feedback is often sought as rank or preference feedback from human raters, as opposed to eliciting scores since the latter tends to be very noisy. On the other hand, RL theory and algorithms predominantly assume that a reward feedback is available. In particular, approaches for online learning that can be helpful in adaptive data collection via active learning cannot incorporate offline preference data. In this paper, we adopt a finite-armed linear bandit model as a prototypical model of online learning. We consider an offline preference dataset to be available generated by an expert of unknown 'competence'. We propose warmPref-PS, a posterior sampling algorithm for online learning that can be warm-started with an offline dataset with noisy preference feedback. We show that by modeling the competence of the expert that generated it, we are able to use such a dataset most effectively. We support our claims with novel theoretical analysis of its Bayesian regret, as well as extensive empirical evaluation of an approximate algorithm which performs substantially better (almost 25 to 50% regret reduction in our studies) as compared to baselines.
-
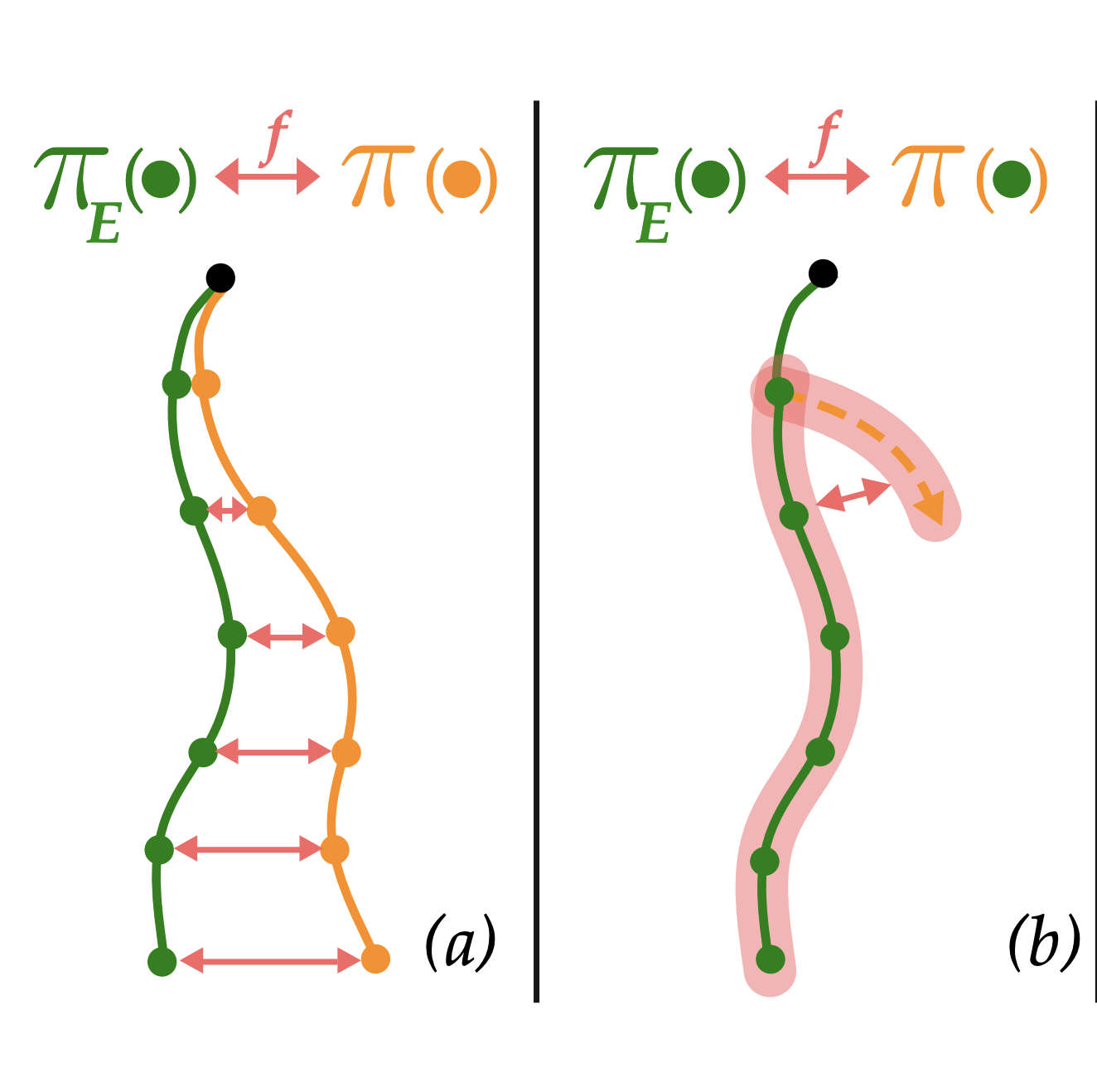
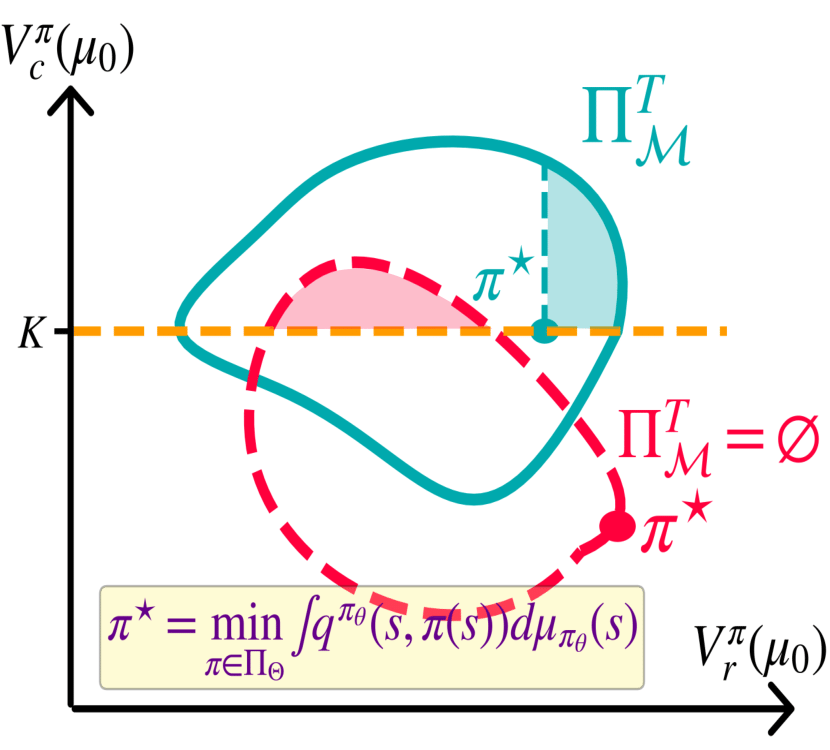
Abstract: In this paper, we present the e-COP algorithm, the first policy optimization algorithm for constrained Reinforcement Learning (RL) in episodic (finite horizon) settings. Such formulations are applicable when there are separate sets of optimization criteria and constraints on a system's behavior. We approach this problem by first establishing a policy difference lemma for the episodic setting, which provides the theoretical foundation for the algorithm. Then, we propose to combine a set of established and novel solution ideas to yield the e-COP algorithm that is easy to implement and numerically stable, and provide a theoretical guarantee on optimality under certain scaling assumptions. Through extensive empirical analysis using benchmarks in the Safety Gym suite, we show that our algorithm has similar or better performance than SoTA (non-episodic) algorithms adapted for the episodic setting. The scalability of the algorithm opens the door to its application in safety-constrained Reinforcement Learning from Human Feedback for Large Language or Diffusion Models.
-

Abstract: Reinforcement Learning (RL) for constrained MDPs (CMDPs) is an increasingly important problem for various applications. Often, the average criterion is more suitable than the discounted criterion. Yet, RL for average-CMDPs (ACMDPs) remains a challenging problem. Algorithms designed for discounted constrained RL problems often do not perform well for the average CMDP setting. In this paper, we introduce a new policy optimization with function approximation algorithm for constrained MDPs with the average criterion. The Average-Constrained Policy Optimization (ACPO) algorithm is inspired by trust region-based policy optimization algorithms. We develop basic sensitivity theory for average CMDPs, and then use the corresponding bounds in the design of the algorithm. We provide theoretical guarantees on its performance, and through extensive experimental work in various challenging OpenAI Gym environments, show its superior empirical performance when compared to other state-of-the-art algorithms adapted for the ACMDPs.
-

Abstract: The past few years have witnessed an increasing interest in improving the perception performance of LiDARs on autonomous vehicles. While most of the existing works focus on developing new deep learning algorithms or model architectures, we study the problem from the physical design perspective, i.e., how different placements of multiple LiDARs influence the learning-based perception. To this end, we introduce an easy-to-compute information-theoretic surrogate metric to quantitatively and fast evaluate LiDAR placement for 3D detection of different types of objects. We also present a new data collection, detection model training and evaluation framework in the realistic CARLA simulator to evaluate disparate multi-LiDAR configurations. Using several prevalent placements inspired by the designs of self-driving companies, we show the correlation between our surrogate metric and object detection performance of different representative algorithms on KITTI through extensive experiments, validating the effectiveness of our LiDAR placement evaluation approach. Our results show that sensor placement is non-negligible in 3D point cloud-based object detection, which will contribute up to 10% performance discrepancy in terms of average precision in challenging 3D object detection settings. We believe that this is one of the first studies to quantitatively investigate the influence of LiDAR placement on perception performance.
-
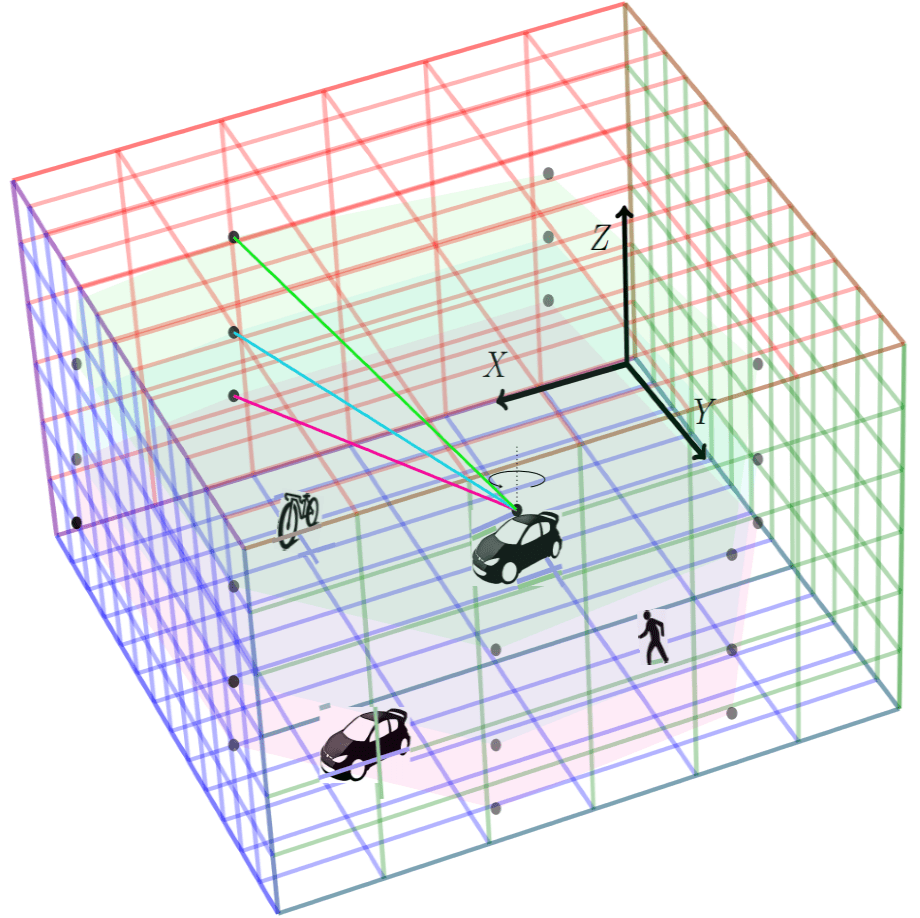
Abstract: Recent years have witnessed an increasing interest in improving the perception performance of LiDARs on autonomous vehicles. While most of the existing works focus on developing novel model architectures to process point cloud data, we study the problem from an optimal sensing perspective. To this end, together with a fast evaluation function based on ray tracing within the perception region of a LiDAR configuration, we propose an easy-to-compute information-theoretic surrogate cost metric based on Probabilistic Occupancy Grids (POG) to optimize LiDAR placement for maximal sensing. We show a correlation between our surrogate function and common object detection performance metrics. We demonstrate the efficacy of our approach by verifying our results in a robust and reproducible data collection and extraction framework based on the CARLA simulator. Our results confirm that sensor placement is an important factor in 3D point cloud-based object detection and could lead to a variation of performance by 10% ~ 20% on the state-of-the-art perception algorithms. We believe that this is one of the first studies to use LiDAR placement to improve the performance of perception.
-
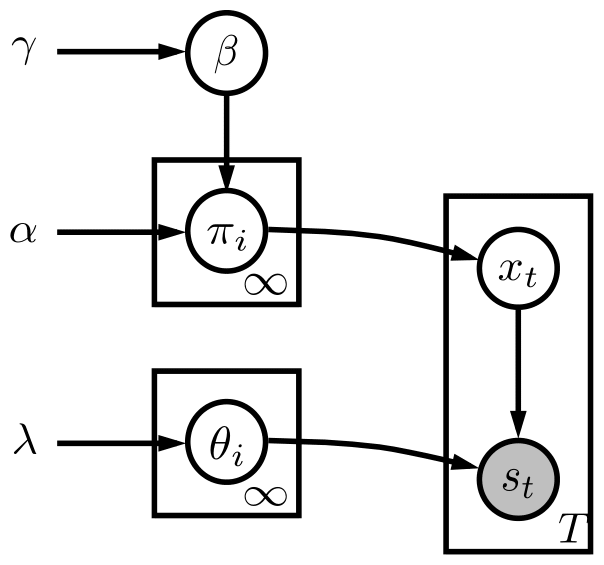
Abstract: Generating multi-vehicle interaction scenarios can benefit motion planning and decision making of autonomous vehicles when on-road data is insufficient. This paper presents an efficient approach to generate varied multi-vehicle interaction scenarios that can both adapt to different road geometries and inherit the key interaction patterns in real-world driving. Towards this end, the available multi-vehicle interaction scenarios are temporally segmented into several interpretable fundamental building blocks, called traffic primitives, via the Bayesian nonparametric learning. Then, the changepoints of traffic primitives are transformed into the desired road to generate collision-free interaction trajectories through a sampling-based path planning algorithm. The Gaussian process regression is finally introduced to control the variance and smoothness of the generated multi-vehicle interaction trajectories. Experiments with simulation results of three typical multi-vehicle trajectories at different road conditions are carried out. The experimental results demonstrate that our proposed method can generate a bunch of human-like multi-vehicle interaction trajectories that can fit different road conditions remaining the key interaction patterns of agents in the provided scenarios, which is import to the development of autonomous vehicles.
-

Abstract: A convolutional neural network (CNN) approach is used to implement a level 2 autonomous vehicle by mapping pixels from the camera input to the steering commands. The network automatically learns the maximum variable features from the camera input, hence requires minimal human intervention. Given realistic frames as input, the driving policy trained on the dataset by NVIDIA and Udacity can adapt to real-world driving in a controlled environment. The CNN is tested on the CARLA open-source driving simulator. Details of a beta-testing platform are also presented, which consists of an ultrasonic sensor for obstacle detection and an RGBD camera for real-time position monitoring at 10Hz. Arduino Mega and Raspberry Pi are used for motor control and processing respectively to output the steering angle, which is converted to angular velocity for steering.
-
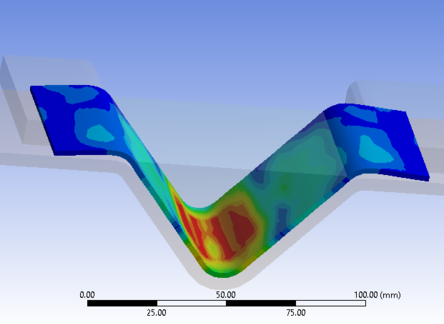 Abstract: This paper presents a review on the superplastic forming of Ti-6Al-4V alloy, which has been used to manufacture parts of complex shapes and geometries. This paper outlines the major work carried out on this front in the past three decades. It covers various aspects related to experimental setups, including the manufacture of dies and their modifications to maintain alloy thickness uniformity after forming. A detailed study of the process parameters has also been done to note the most important physical conditions required for successful forming. This is followed by the influence of microstructure, modern applications of superplastic forming of different titanium alloys and is concluded with an insight into the future work and progress in this field.
Abstract: This paper presents a review on the superplastic forming of Ti-6Al-4V alloy, which has been used to manufacture parts of complex shapes and geometries. This paper outlines the major work carried out on this front in the past three decades. It covers various aspects related to experimental setups, including the manufacture of dies and their modifications to maintain alloy thickness uniformity after forming. A detailed study of the process parameters has also been done to note the most important physical conditions required for successful forming. This is followed by the influence of microstructure, modern applications of superplastic forming of different titanium alloys and is concluded with an insight into the future work and progress in this field.
Projects
-
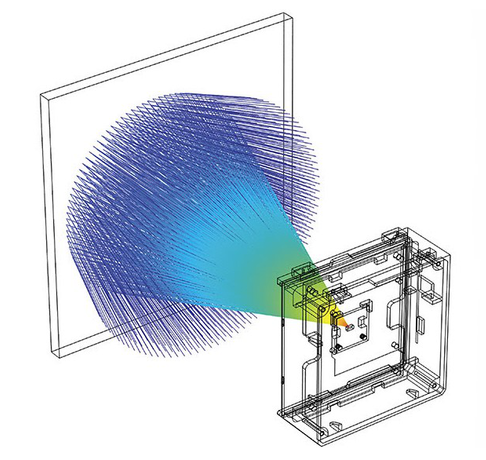
Abstract: A LiDAR provides accurate 3D views and precise distance measurements under uncertain driving conditions. However, its implementation remains costly. To tackle this issue an effort to maximize the utility of the LiDAR is made. Since, at a high-level, the task of a LiDAR is to detect objects, an easy-to-evaluate cost function which minimizes the maximally undetected subspace is used. Different LiDAR configurations in the CARLA simulator are used and for each, depth camera images are converted to LiDAR point clouds since CARLA’s LiDARs are not accurate. The perception area is used to construct a design procedure to solve the optimization problem described above based on weighted region of interests around the vehicle. The weighted regions are obtained when a subspace cuts a cube and the cube’s weight is incremented by 1. Now, the task becomes to maximize for all LiDAR configurations and find the optimum for a particular number of LiDARs.

-
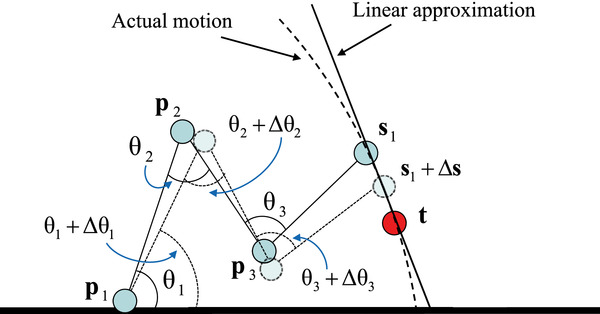
Abstract: Spatially hyper redundant systems have more number of controllable Degrees of Freedom (DOF) as compared to their actual DOF. These systems have infinite number of solutions for a given state space reach making it complex to develop proper inverse kinematic solution. Adapting the optimization methods only help to arrive at the promising Inverse Kinematic (IK) solution. The second part of the project involves implementation and simulation of computed torque control method for a 2-DOF manipulator sing MATLAB/Simulink. Computed Torque Control is a powerful non-linear controller which uses feedback linearisation to compute the required arm torques required for movement. The robot model is designed using the SimMechanics library of Simulink.
-
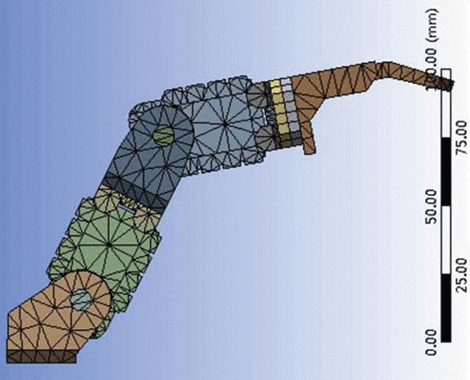
Abstract: This study aims to identify the best possible material for production of liners for prosthetic limbs. Based on the standard Galerkin finite element method in space and Crank-Nicolson difference method in time, the semi-discrete and fully discrete systems are constructed. The code is written in C++ and MATLAB, and deformation plots of different loading conditions for different materials are analyzed. The code is a general approach written for a (n x m) meshing domain and can be refined as per the user preference based on the desired accuracy. The code was validated with simulations on ANSYS Static Structural providing a green signal for further research. Further work to incorporate the nonlinear constitutive behavior of silicone will be done to test whether silicone is really the best economic material in the market available.